どうも、すなです。
セキュリティシリーズのアウトプットがまだ残ってるけど、今回はTDDについて。
初のLT登壇をこれでやってスライドとか作ったのでブログでもアウトプットしておく。
TDDはちゃんとやろうと思ったら細かいルールみたいなのがたくさんある。
(TODOリストの作成とか三角測量とか)
ここではTDDをやることのメリットと大雑把にどのようにやるのかにフォーカスしてまとめる。
多少オリジナルも入っていて、厳密なTDDのやり方ではないかもしれないけど要点は抑えられていると思う。
テストを書く意義
そもそもテストを書く意義については以下のようなメリットがある。
・バグを減らすため
・運用保守しやすくするため
・リファクタリングしやすくするため
多分そんなことはみんなわかってるんだけど、何かとないがしろにされがちなテスト。
理由として一番大きいのはテストを書く時間がないからってことだと思う。
それに関してはテストに詳しい偉い人がこう言ってた。
「テストを書く時間がないのではなく、テストを書かないから時間がないのです」
個人的にこの言葉は結構キャッチーだし、わかりみが深くて好き。
確かにテストを書くと記述量は間違いなく増える。
でもそれによってわざわざ手動でテストしなくてもよくなるし、リファクタリングの時にも記述は変えたけどこれまで通り動作するということに自信を持てるようになる。
工数とか時間とか何かと目先のことだけで語られがちだけど、長い目で見たら運用コストやデバッグの時間は減るしトータルの工数や時間は減るよねと思ってる。
TDDだと実装段階で実装のミスにも気づきやすくなるから自分はわりと好き。
前置きはこれくらいにして、ここからはテストは書くべきという前提の元で話を進める。
最後にはどういう場合にTDDで開発すると良さそうかという現時点での個人的なまとめも書いておく。
TDDとは
TDDとはTest-Driven Developmentのことでテスト駆動開発と呼ばれる。
どういう開発手法かと言うと、テストを最初に書いてそのテストが通るようにコードを実装する方法である。
細かい定義とかは違うかもしれないけど、実際の作業としてはこの理解でいいと思ってる。
その目的は「動作するきれいなコード」を実装すること。
TDDによるメリット
TDDによるメリットは目的の通り動作するきれいなコードを実装することはもちろんだが、実装レベルで考えると個人的には以下の通りだと思ってる。
・バグを早期に発見できる。
・適切な粒度で関数を実装できる。
・実装すべきコードのゴールを明確にすることができる
1つめと2つめは後ほど詳細を記述する。
3つ目に関して、やり方はこの後具体的に見ていくが、TDDでは先にあるべき姿をテストとして定義するため先にゴールを明確にすることができる。
これによってそのゴールに沿った形で実装していくことができるため、実装が捗る。
TDDのやり方
まずここでTDDのやり方を記載した後で、実際に具体例を用いて見ていくという形にする。
TDDは以下のようなサイクルを回すことで開発を進めていく。

1. RED
まず最初のステップで動作しない失敗するテストを書く。
失敗するテストを最初に書くと言うのがポイント。
なぜなら失敗することを確認せずにテストを書いてそのテストが通った時、実装内容に関わらず通るテストを書いてしまっている可能性があるから。
いかなる時も通るテストは意味がないどころかむしろとても怖い。
人狼でいうところの狂人である。
占われても人間なのに実は人狼サイドでした。
テスト通したら通るのに実はぶっ壊れてました。
そんなプログラムが潜んでたら怖くない?
テストってのは失敗することにも意味があるので、失敗すべき時に失敗し、成功すべき時に成功することを確認する必要がある。
よって最初にちゃんと動作しないことを確認する。
2. GREEN
次に1のREDの段階で書いた失敗するコードを最短で通る形で実装する。
この最短で通る形でというのがポイント。
ここでは実装の詳細な内容は気にしない。
とりあえずテストが通るようになれば一旦はok。
なのでコードのきれいさなどもここでは気にしない。
なんでもいいからテストが通ることを確認することで、このテストはちゃんと動作しているということを確認できる。
大きめの実装をした後にテストが通らず、そもそもテストの方が間違ってたみたいなことを防げる。
テストを最初に書いてあるべき姿を定義、それがちゃんと通るということを最短ルートで確認する。
3. REFACTOR
最後のステップでリファクタリングを行う。
2のステップで実装の詳細な内容を気にせず、とりあえずテストが通る形で実装をした。
そのためテストが通る形にはなっているが、本来あるべき姿にはなっていない。
よってここであるべき姿に修正していく。
TDDにおけるリファクタリングは一般的な意味をもう少し狭義にしたもので、
「成功しているテストが成功しているままでコードを改善すること」である。
つまり2のステップでGREENになった状態をキープしたままコードの実装をあるべき姿に変えていく。
これによって実装内容が意図したものになっていることを確認しながら実装を進めることができる。
これは完全に個人的な認識だが、リファクタリングは3のステップというより1と2のステップが終わった後にまた1と2のステップを繰り返していく過程のことだと思っている。
図にするとこんな感じ。

これに関してはどこを見てもこういう図にはなってないから間違ってる気はするんだけど、個人的にはこっちの方がしっくりくる。
このようにして
失敗するテストを書く → とりあえずテストを通す形にする → テストが通る状態のまま本来あるべき姿に修正する
という風に実装していくのがTDDの大まかなやり方である。
さて、TDDの目的は「動作するきれいなコード」を書くことであった。
以上の流れを見ればわかるように、TDDでは
「きれいな設計をしてその通りに動作するコードを書く」のではなく、
「動作する汚いコードを実装して、動作するままきれいにしていく」のである。
具体例 ~ 実際にやってみた ~
やり方だけ見てもイメージしにくいので実際にやってみる。
今回はFizzBuzzを用いて説明する。
以下のような仕様のfizzBuzzという関数を実装することを想定。
引数に数値型のnを受け取り、3の倍数なら”Fizz”、5の倍数なら”Buzz”、15の倍数なら”FizzBuzz”、それ以外なら数値をそのまま返す。
1. RED
実装を書く前にテストを書くというところから始める。
以下の画像の左が実際の実装。右がテスト。
いつもこんな感じでコードを左右で分割してテスト見ながら実装を書くってことをしてる。
こうすると中々捗る。

テストの内容は以下のような感じ。
・まずテストしたい関数をimportしてくる。
・次にテストする関数の情報を書く(“FizzBuzz”のテスト)。
・テストしたいケースを書く(“3の倍数の時にFizzと返す”)。
・実際にテストしたい関数に適切な引数(ここでは3)を入れて結果をresultに格納する。
・その結果が期待する通り(“Fizz”)になっていることを検証する
これがまず期待する動作をテストとして定義する段階。
ここでは当然テストは通らずREDになる。
なぜならそもそもテストしたいfizzBuzz関数が定義されていないから。
このようなコンパイルエラーもREDとみなす。
先に説明した通りここでテスト通ったら困るよね?
ちゃんとテストが失敗することを見届ける。
2. GREEN
さて、次にとりあえずテストが通る形で実装をしていく。
コードのきれいさとかは無視。とりあえずテストが通るようにする。
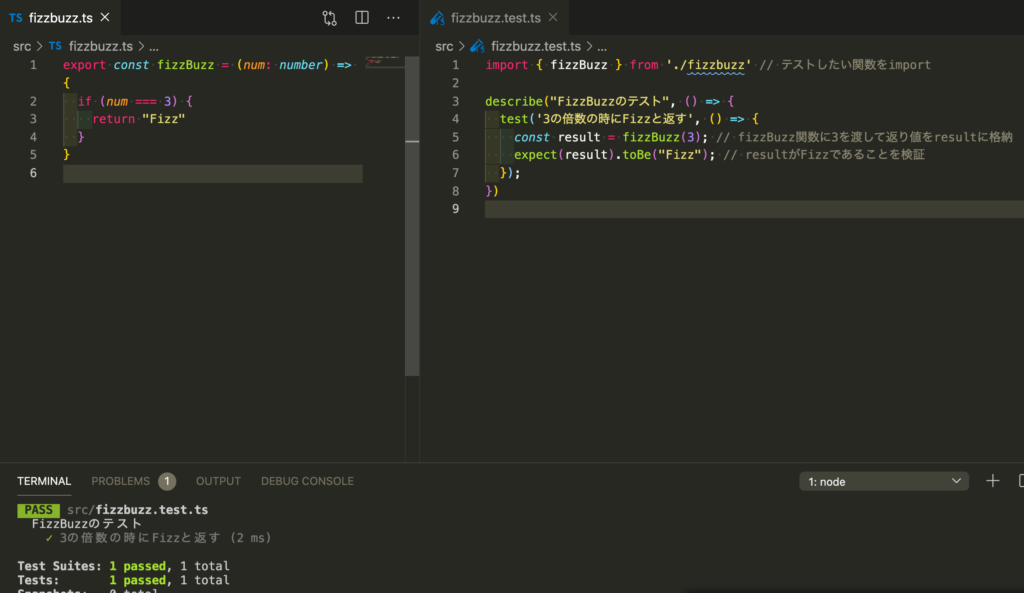
実際に関数を実装して、引数が3の時にFizzと返すようにした。
3の倍数なので本来は6とか9でもFizzと返すようにすべきだが、ここでは一旦無視。
とりあえずテストを通すことが目的なので代表的な3の場合で実装する。
(これは一例なので他の方法でもテストが通ればなんでもいい)
3. REFACTOR
無事にテストが通ることを確認できたので、これをあるべき姿に修正していく。
2のステップで最短でテストを通すことを目指したばかりに、3ではテストが通るが6とか9では通らない形になっている。
よってこれを3の倍数という条件に変更する。
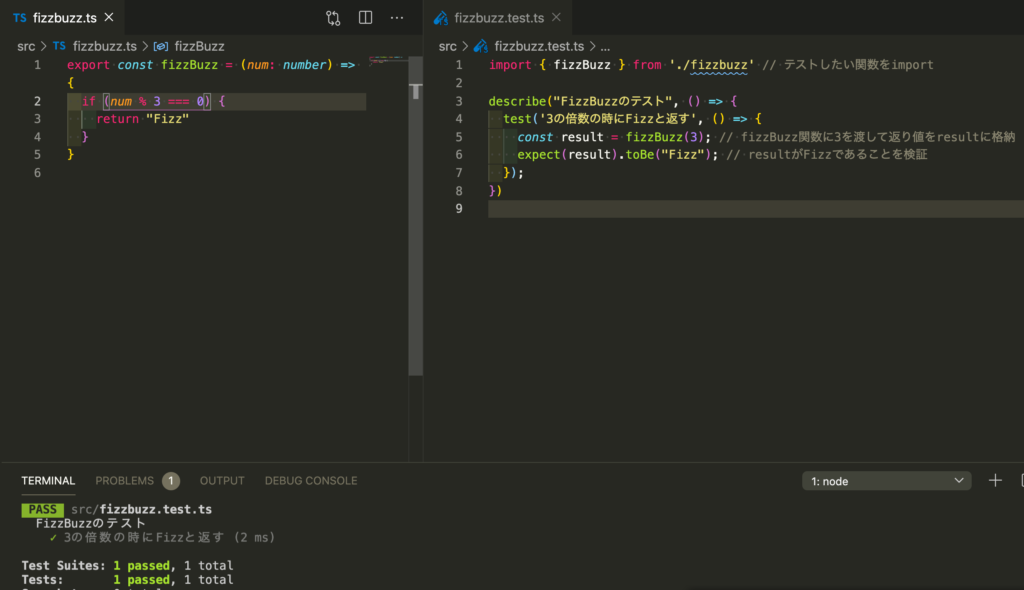
3の倍数という条件に変えて無事テストが通ることを確認できた。
このようにGREENの状態をキープしつつ実装を変えることができたので、リファクタリング後のコードも問題ないと安心できる。
他の条件の時も同じようにして進めればok。
ここは人によって変わるのかもしれないが、個人的にはテストのところに定義を最初に網羅的に書いておくことが多い。
多すぎる場合は区切るなどケースバイケースだが、こんな感じ。
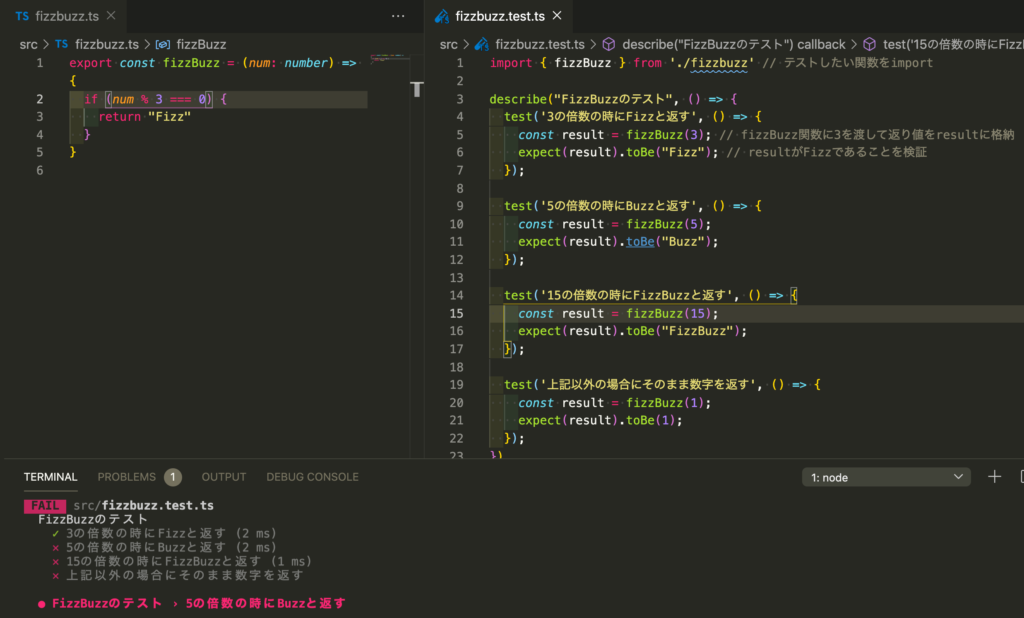
あとは通ってないテストを右の仕様を見ながら実装をしていく。
こんな感じで先にあるべきゴールを定義してそれに沿って実装していけるってのが、やるべきことが明確になるので実装におけるメリットかなと個人的には思ってる。
あと通ってないテストが1つずつ通ってくのは単純に楽しい。笑
TDDで実装することでバグを早期に発見できる例
メリットのところであげたTDDによってバグを早期に発見できる例を見ていく。
先ほどのFizzBuzzの続き。
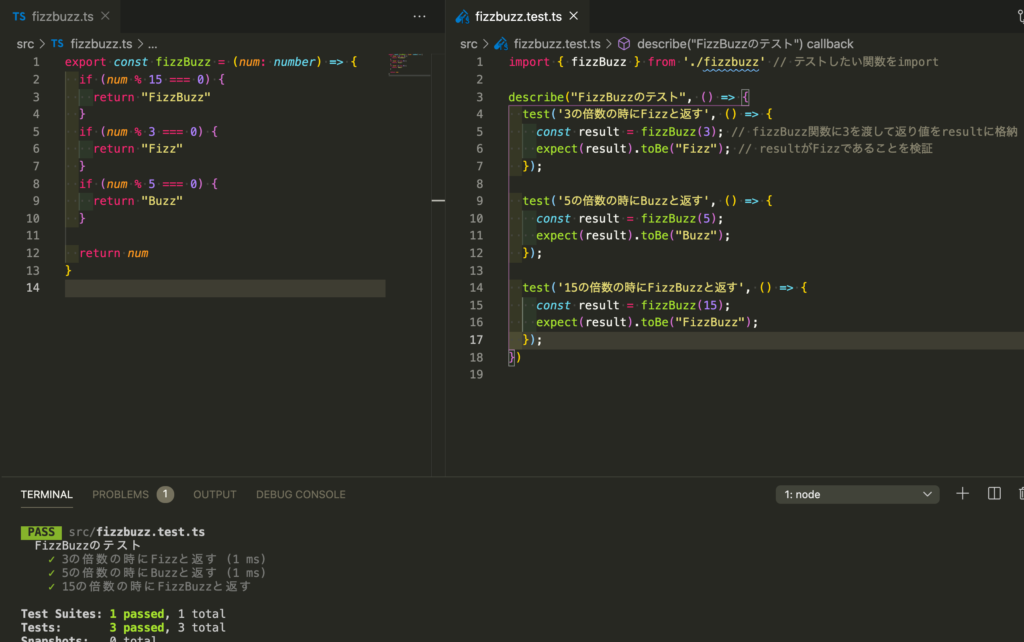
15の倍数の時にFizzBuzzと返すように実装したつもりが、以下のようにするとテストが通らなかった。
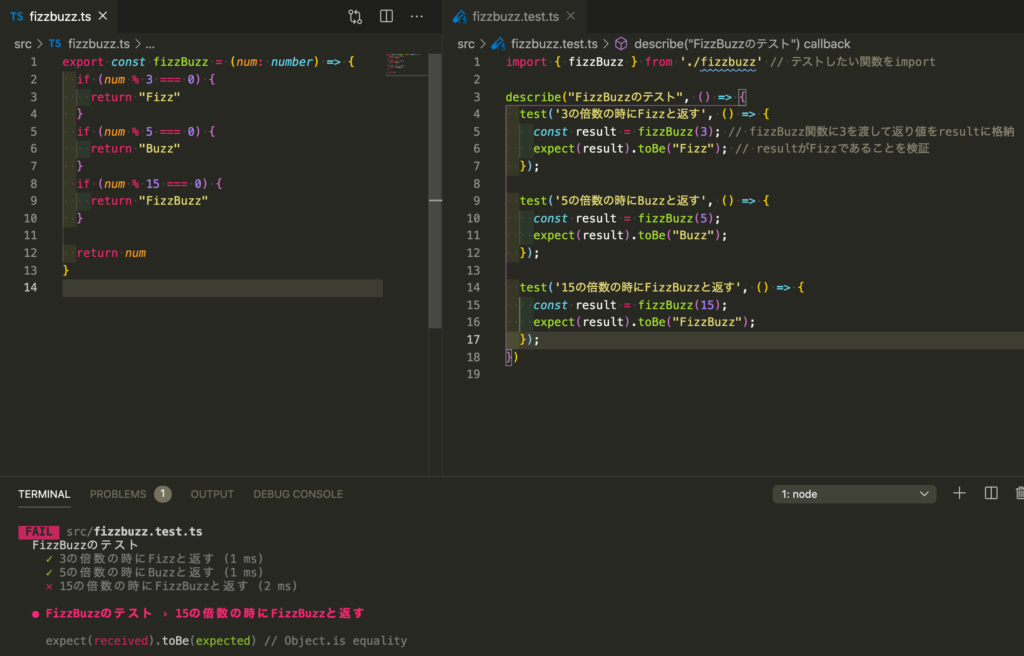
実際に出力された結果を見てみると以下のようになっている。
つまり、FizzBuzzとなることを期待したのに実際に得られた結果はFizzだったのである。
それもそのはずで15は15の倍数であるが、3の倍数でもある。
プログラムは上から順に実行されるため先に3の倍数の条件に該当するためFizzと出力されたのである。
したがって、以下のように訂正するとテストが無事通り期待通りの実装になっていると自信を持つことができる。
もちろんこれは簡単な例だが、実際に普段実装するコードはもっと複雑なものが多い。
ここで重要なのは、実装している段階でテストが通らないことによって実装が間違っていると気づくことができる点である。
先に実装を書いてからテストすると、間違ったまま実装をしていって手戻りが大きいということもありえる。
ましてやテストを書いていないと、この関数が他の関数から呼び出されていてプログラムを全体で通した時に期待した動きになっていないなどの場合、問題を切り分けるデバッグ作業が大変になる。
TDDであれば問題があるのは今テストが通ってない場所だと明確に言えるため、デバッグの時間が大幅に短縮される。
TDDのサイクルの粒度
先ほどの具体例で3の倍数の時にFizzと返す場所で最初の実装では if (num % 3 === 0)ではなくif (num === 3)と書いた。
正直これくらいであれば最初から3の倍数としてもいい気もする。
というか自分ならそうする。
重要なのは実装の複雑さと自分の自信に応じて歩幅を変えてしかるべきということだと思っている。
今回の例ももっと歩幅を刻むならif文を書かずにそのままreturn "Fizz"だけを書いてもテストが通ることは確認できるのだ。
3の倍数だけ歩幅を小さくして自信が持てたなら、5の倍数の時はいきなり倍数として書いてもいいと思う。
あとは本当にその実装が正しいかを確かめるためにもう一つ別のテストケースを書くような三角測量と呼ばれる手法もあったりするが、これも状況に応じて使い分ければいいと思う。
この辺の細かな手法はあんまり気にしなくていいんじゃないかという気がしている。
TDDの使いどころ
ここまでTDDのメリットややり方を見てきた。
個人的にTDDは楽しいしメリットも多く感じられるので好き。
じゃあ開発はいつでもTDDでやるのがいいのかというとそんなことはないと思ってる。
以下は完全に現時点での個人的な見解。
サーバーサイドの実装
単体テストや簡単な結合テストはTDDの恩恵が大きいと思ってる。
というのも実装すべき範囲が大きくなるにつれてDBアクセスのmockを用意したり、別の関数を呼び出したりと処理が複雑になっていくので最初にGREENにするステップが重くなってしまうから。
逆に言えば、単体テストの場合は実装が苦しくないくらいの粒度で関数を適切に切り分けるようになる。
これがメリットであげた2つめの事項。
関数はできるだけ疎結合にしておくべきだと思っていて、実装している時にグローバル変数を参照していてテストしにくいとかがあればこの段階で気づけるため、適切に修正をすることができる。
個人的にはこのメリットは結構大きい。
TDDにすることによって結果的に可読性が上がる。
テストしやすい粒度で実装しようと思って実装し始められて、テストしやすい形で実装し終えられる。
フロントエンドの実装
フロントエンドとくくったがReactで考える。
Reactのテストはまだあまり精通してないので、あくまでも現時点での見解だが、ロジック部分のテストに関しては上記と同様のスタンスでいる。
つまり、TDDの恩恵は大きそうだと思っている。
Reactの場合、コンポーネントのテストもあるが、個人的にはこれをTDDでやるメリットは薄そうだと感じている。
理由はテストを通しただけでは安心できないから。
テストが通ってるからブラウザで確認しないとはならないし、結局ブラウザで確認した後に実装そのものを変えたくなることもある。
テストを書いた方がいいとは思うけど、実装に先立ってテストを書く恩恵はあまり得られないんじゃないかなーと。
TDDのメリットデメリットまとめ
最後に個人的見解も踏まえてメリットデメリットをまとめる
メリット
デメリット
慣れるまでは最初にテストを書くというのが違和感に感じた。
なので小さい関数のユニットテストで慣れていく、正常系のテストだけでもやってみるというのが良さげかなと思っている。
おまけ
TDDとはちょっとズレるけどTDDを勉強していた時に知ったいい感じのtipsがあったので書いておく。
テストを書く意義について、テストは実装の仕様書になるよという話。
実務でコードを読んで仕様を把握するということがたびたびあるけど、その時に実装内容を読んで理解するのはちょっと時間がかかるし大変。
そんな時にテストがちゃんと書かれていればテストを見ればいい。
そこにはそのテストがどういうケースでどういう値を返すものなのかが書いているから。
FizzBuzzだとあんまりイメージできないかもだけど、以下のようにfizzBuzz関数の内容を知りたかったら右側のテストを見れば一目瞭然。
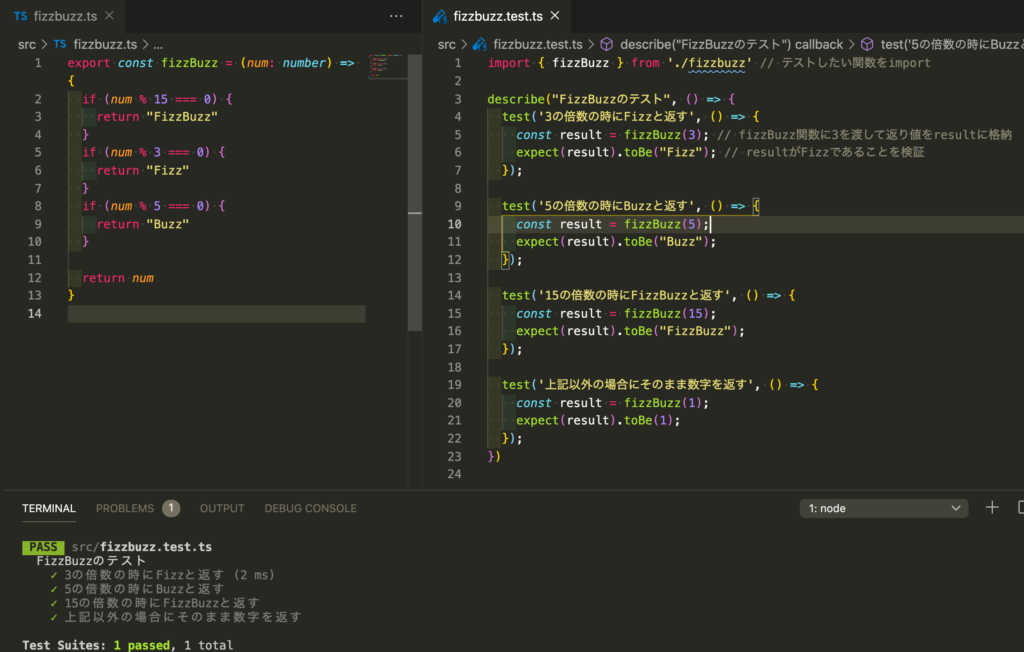
なので実際に実装する時にはプログラム的な書き方ではなく、できるだけ実際の仕様書っぽい書き方をするようにしている。
たとえば予約を取る関数があったとして、そこで条件分岐する場合は以下のように書く。
×: ユーザーIDに紐づく予約IDがある場合は、falseを返す
○: ユーザーに紐づく予約が既にある場合は、予約ができない
テスト対象のコードの中身ではなく、外から見た動きに注目してテストを書くいわゆるブラックボックステストみたいな感じ。
正解は分からんけど、後々仕様書的に読むことを考えると個人的にはこっちの方が好き。
参考
・テスト駆動開発
・TDDのライブコーディングをするYoutube
https://www.youtube.com/watch?v=Q-FJ3XmFlT8&t=2248s
2時間くらいあって長いけど、わかりやすくてオススメ!