高負荷・低レイテンシーなサービスを運用する上でキャッシュは欠かせません。
普段広告配信サービスを運用しており、秒間1万以上のリクエストを50ms以内にレスポンスする必要があるため、キャッシュ戦略は非常に重要なものになっています。
そして各データをどこにどれくらいの期間でキャッシュとして保持するかは、エンジニアとして腕の見せ所です。
今回は会社の他のチームが実践していたキャッシュ戦略が目から鱗だったので、その方法を備忘録として記載しておきます。
そして、実際にその戦略を取り入れた前後での各種メトリクスの変化なども併記します。
なお、一口にキャッシュと言っても様々なレイヤーでのキャッシュがあり得ると思いますが、ここではDBの情報をキャッシュしてアプリケーションサーバーから使用する場合を考えます。
元々のキャッシュ戦略
元の設計は以下のようになっていました。
(実際のキャッシュはサーバーのメモリ上に存在していますが、便宜上別リソースとして分けています)
クライアントからリクエストがあった時に、まずキャッシュサーバーから情報を取得して、取得できなかったらDBから取得し、キャッシュサーバーに格納してクライアントにレスポンスを返しています。
キャッシュのTTL以内に同じリクエストが来た場合はキャッシュサーバーからデータを取得できるので、DBにリクエストが行かず負荷軽減とレスポンス速度向上に繋がります。
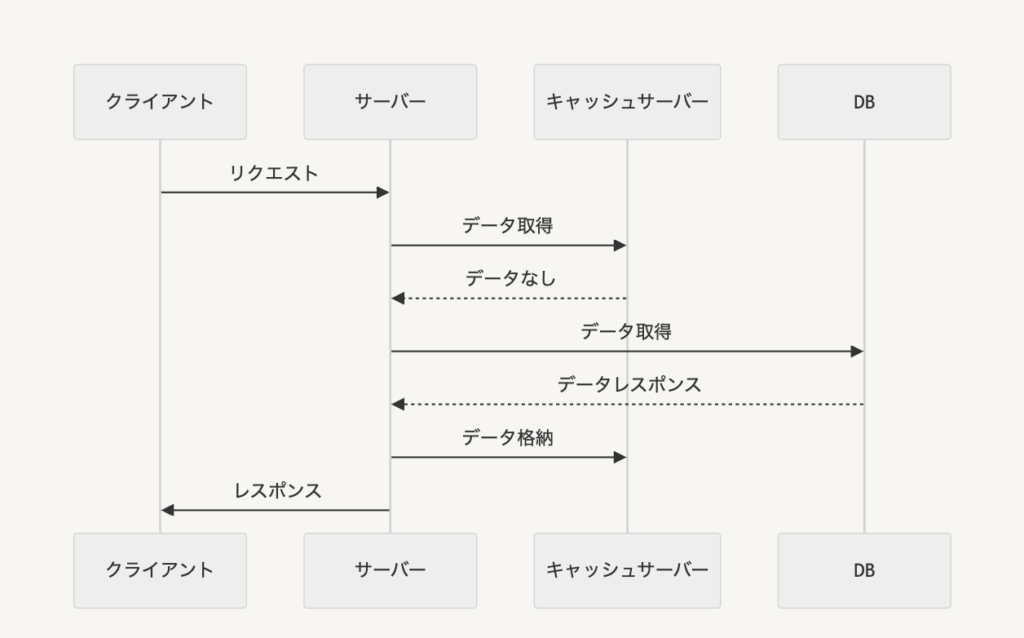
わりとよくある一般的な構成なのではないかと思います。
この構成の問題点は、1万RPS以上のような大量のリクエストがあるサーバーでは、キャッシュのTTLが切れた時に一時的にDBへのアクセスが集中するThundering herd問題が起こることです。
(Goだとsingle flightのようなライブラリでDBへのアクセス数を減らすことはできそうですが、今回は諸事情によりやっていません)
新しく採用したキャッシュ戦略
では新しく採用したキャッシュ戦略はどういうものか、一言で言えば「リクエストとは関係ないところで非同期バッチ処理でキャッシュを更新し続ける」というものになります。
まず、キャッシュサーバーへのデータの格納は、リクエストとは関係ないところで一定期間ごとに更新処理を行います。
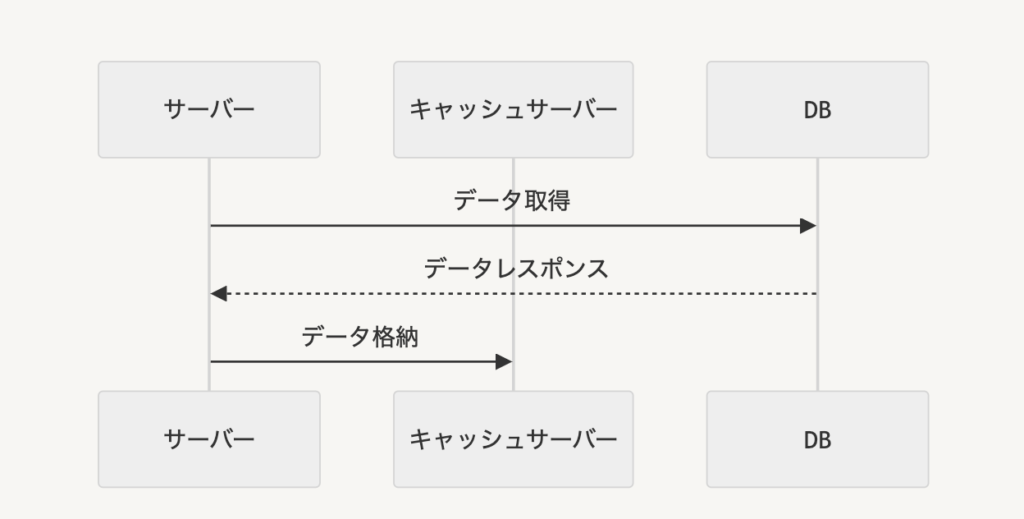
この時、リクエストで使用されうるあらゆるデータに対して、それらのkey-valueをキャッシュとして保持しておくことになります。
一方で、クライアントからのリクエスト時にはオリジンであるDBには一切アクセスせず、キャッシュサーバーの情報だけを使います。(キャッシュにデータがない = DBにもデータがないとなります)
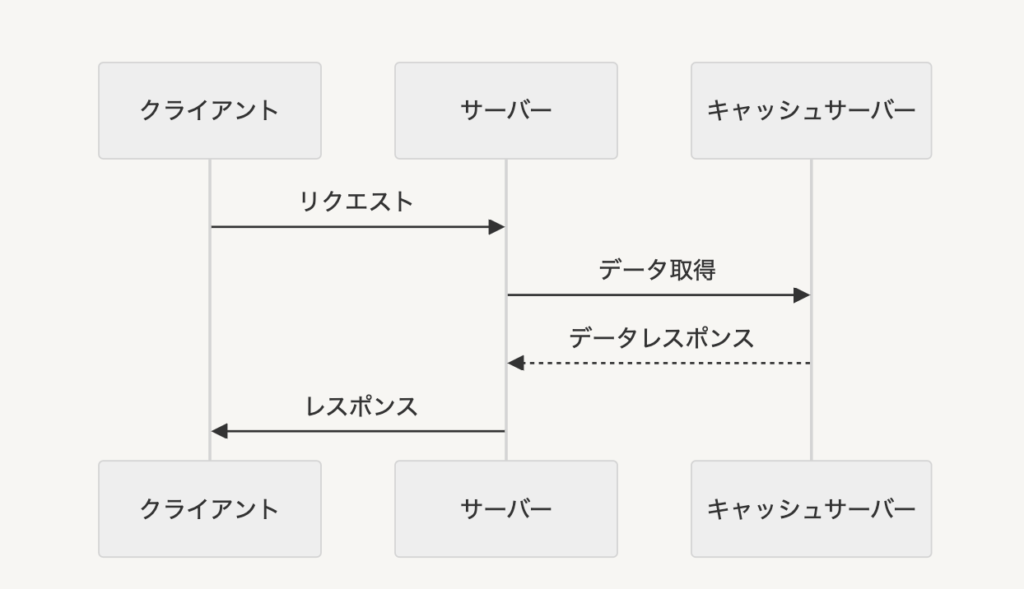
合わせて全体像を見ると以下のようになっています
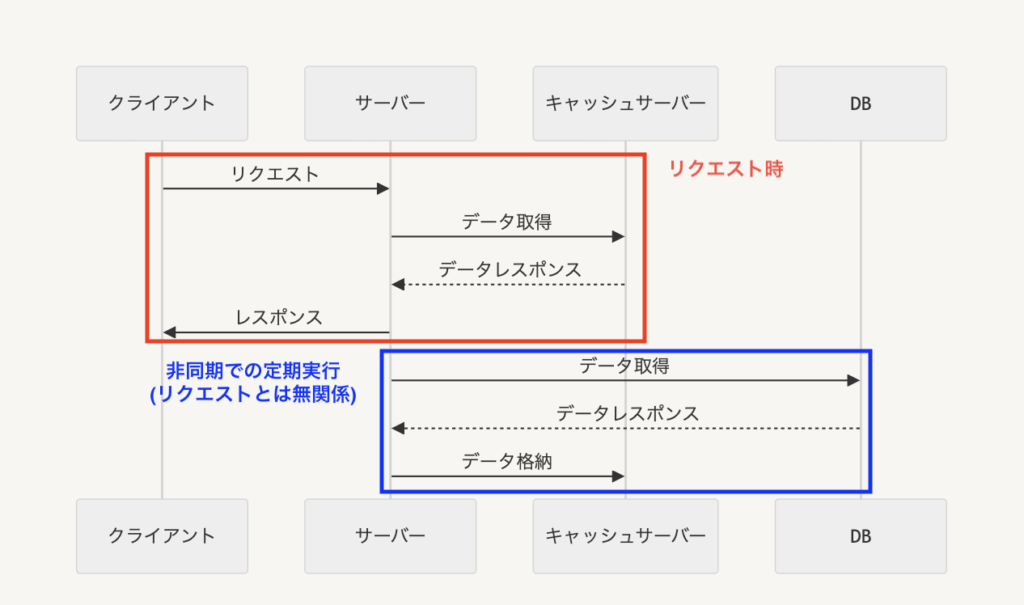
リクエスト時にはキャッシュしか見に行かなくなったので、キャッシュのTTLが切れた時に一時的にDBへのアクセスが集中するThundering herd問題は起こらなくなります。当然それによってレスポンス速度が悪化することもなくなり、パフォーマンスが安定します。
ただし、いくつか考慮すべき点があると思うので、思いつく限り列挙しておきます。
キャッシュに保持するデータ量
この機構では、「あらかじめリクエスト時に必要になりうるあらゆるパターンでキャッシュを保存しておく」必要があるため、そのパターンが膨大な場合には慎重な検討が必要そうです。
たとえばユーザー情報をキャッシュに保持する場合、従来ではそのユーザーの情報をwhere句で指定して取得すればよいのですが、この機構の場合リクエストされうる全てのユーザーの情報をあらかじめ取得してキャッシュに適切なkey-valueで保持させておく必要があります。
当然1回のクエリで取得するデータ量は大きくなりがちです。
とは言え、リクエストとは関係ない場所で非同期に取得してキャッシュへの格納処理を行っているため、膨大な時間がかかるほどのデータ量でなければその処理の重さ自体はあまり気になるケースがない気もします。
逆に、多少処理時間がかかるとしてもリクエスト時に処理時間が短くなるようなデータ構造でキャッシュに保持させておくといった戦略も取ることができるようになります。
膨大なデータ量の場合は、どちらかと言うとデータ量によるキャッシュサーバーのメモリ容量の方が問題かもしれません。
「あらゆるパターンのためにキャッシュに保持しているが、90%以上はほぼ使われていない」みたいなケースだとコスパが悪いかもしれませんが、その場合はその10%分だけこの機構で常に更新し続けておくといったハイブリッド戦略でもいいかもしれません。
キャッシュのTTL
TTLはキャッシュを更新する期間より長く設定しておく必要があります。
そうしないと次の更新のタイミングまでの間にデータがないといった状況になってしまうからです。
また、常にキャッシュを上書きするため上書きされるデータに関してはキャッシュ更新のタイミングで新しいデータになりますが、上書きされなかったデータはTTLの保持期間分まで存在し続けます。
したがって、常に更新するから長めのTTLでいいというわけではなく、本来参照されるべきではないデータが最大でキャッシュのTTL時間分参照されてしまうことは留意すべきです。
アプリケーションによってこの辺を加味しつつ、キャッシュ更新頻度とTTLの設定を行うとよさそうです。
実装方法
Golangでのサンプルコードを記載します。
大枠の方針としては、main goroutineとは別でgoroutineを起動させておき、そこで無限ループで一定間隔でキャッシュの更新処理を行います。
そのため、以下のコードのSyncをサーバー起動時に呼び出しておけばそれでokです
(constructorなどは省略)
// TTL以下に設定する
const (
fooInterval int = 3 * 60 // 3min
barInterval int = 2 * 60 // 2min
bazInterval int = 1 * 60 // 1min
)
func Sync() {
syncPeriodically(fooInterval, RefreshFoo)
syncPeriodically(barInterval, RefreshBar)
// 同じタイミングでキャッシュを更新したいものはまとめる
syncPeriodically(bazInterval, RefreshBaz, RefreshBaz2, RefreshBaz3)
}
func syncPeriodically(intervalSec int, fns ...func(ctx context.Context) error) {
ctx := context.Background()
env, err := client.LookupString("SYSTEM_ENV", "local")
if err != nil {
logger.Log.Errorf("failed to lookup SYSTEM_ENV: %v", err)
return
}
// dev, stgでは動作確認をスムーズに行えるように一律10秒にする
if env != "prd" {
intervalSec = 10
}
go func() {
defer func() {
if r := recover(); r != nil {
logger.Log.Errorf("INTERNAL SERVER ERROR: %v\nStackTrace:\n%s", r, debug.Stack())
}
}()
for {
for _, fn := range fns {
if err := fn(); err != nil {
logger.Log.Errorf("failed to sync cache: %v", err)
}
}
// 各クエリのsyncが同時に起こるとDBへの負荷が集中するため、ランダムで0 ~ 10秒ずらす
time.Sleep(time.Duration(intervalSec+rand.Intn(10)) * time.Second)
}
}()
}
メトリクスの変化
最後に、この機構に移行したことによってどれくらいクエリ数が減ったのかを見てみます
11:00過ぎ辺りにウォーターフォールしてるのがとあるクエリ処理を今回の機構に移行したときのものです
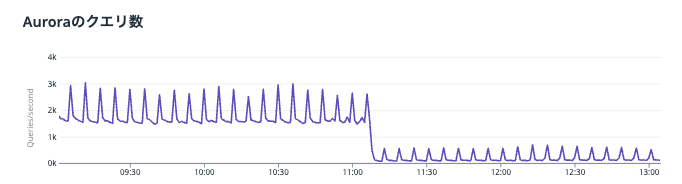
かなりクエリ数が減っているのが一目瞭然
数分間隔でスパイクっぽくなってるのがまさにキャッシュが切れるタイミングで、Thundering herd問題によってクエリ数が一時的に増えてるのがわかります
一部のクエリを移行しただけなので、全体的にはクエリ数は減ったもののまだ一定間隔でスパイクしています
これがサーバー上の全てのDBアクセス処理を今回の機構に移すとこうなりました
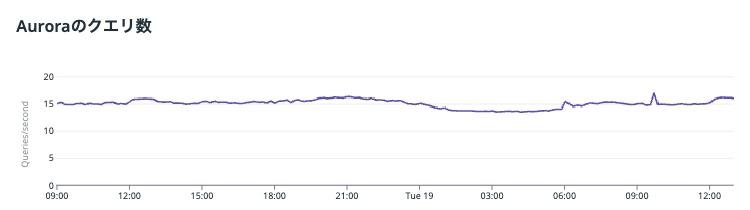
太平洋かってくらい穏やかですね
1万RPSくらいあるのにも関わらず、クエリ数は数十/sec程度で済んでいます
まとめ
自分の中ではキャッシュ機構って「キャッシュ見に行って無かったらorigin見に行く」ってのが当たり前になってたので非常に学びが深かったです
その後ISUCON本見たんですが、この辺のこともちゃんと書いてました
読んだはずなのに覚えてなかった…
もっかい読み直します
この記事が参考になったからコーヒーくらいおごってもいいぜという方は、以下からサポートいただけると次の記事書くモチベになりますのでよろしくお願いします
