業務でGraphQLを使っていることもあって、GraphQLについてちゃんと概念と使い方を勉強した。
ここでは具体的な操作方法といったことではなく、GraphQLとは何か?メリットとデメリットは何か?といった概論についてまとめる。
以下のオライリーの本を読んだがなかなかわかりやすかった。
オライリー本はとっつきにくいと思ってたけど、案外そんなこともなかった。
食わず嫌いよくない。
前置きはこのくらいにして本題に入っていく。
本以外にも結構いろんな記事出てるからそれらについてもいくつか読んだ内容をまとめた。
GraphQLって何?
Facebookが開発しているWeb APIの規格。
もうちょっと平たくいうと、APIに対するクエリ言語のこと。
すなわち、APIサーバーに対してデータの問い合わせをすることができるクエリ言語。
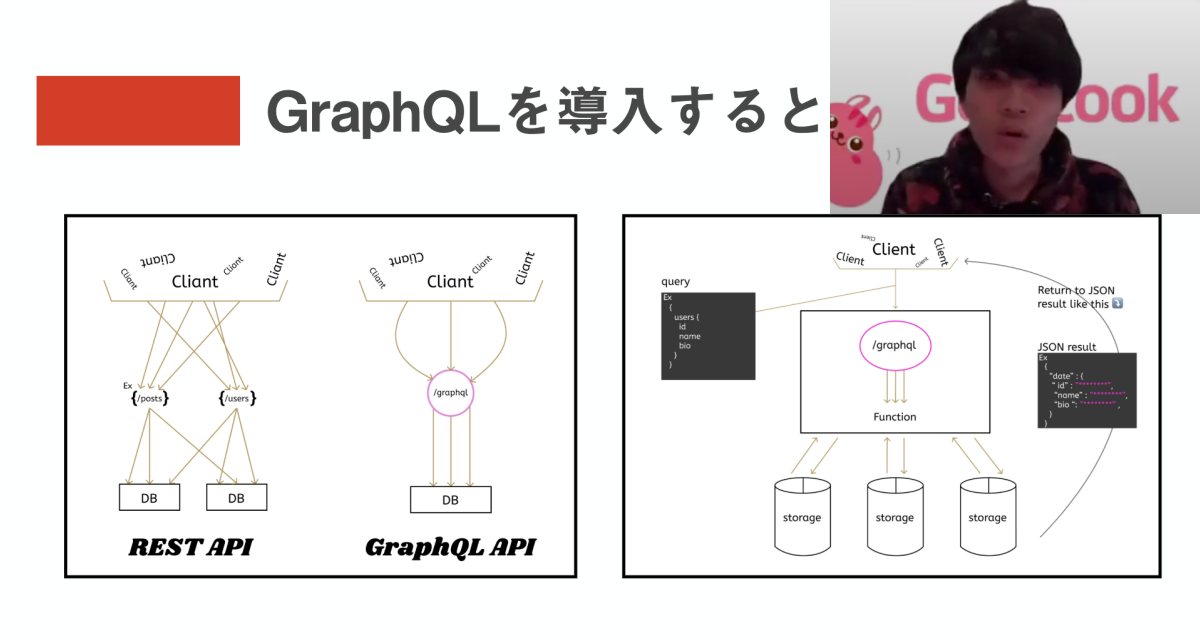
これまでよく使われてきたWeb APIの規格はRESTというもの。
APIサーバーに対して、GET, POST, PUT, DELETEなどを行うのはRESTという規格に基づいている。
詳しくは下記参照。

GraphQLとはRESTでの様々な課題を解決するためにFacebookが開発した規格である。
RESTの課題とは?
GraphQLによって解決できるRESTの課題は主に以下の3つ。
① レスポンスされるデータに過不足が生じる
② 機能ごとにエンドポイントの数が膨れ上がる
③ APIドキュメントの管理、メンテが面倒
以下ではこれらのRESTの課題をもう少し詳しく説明する。
レスポンスデータの過不足
レスポンスデータが過剰な場合と不足している場合について分けて見ていく。
過剰な取得
たとえば人物の情報を取得できるhttps://example.com/api/people/1 みたいなエンドポイントを考える。
ここにGETリクエストを送ると以下のJSONのようにその人物のプロフィール情報を得られるとする。
{
"name": "suna",
"age": 25,
"gender": "male",
"height": 200,
...
}この時、クライアント側で欲しい情報はその人物の名前と年齢だけだったとしても、レスポンスの形はサーバーの方で決められているためクライアント側で必要のない情報も全て取得してしまい、無駄が生じる。
不足した取得
先ほどの例の続きで、あるユーザーのプロフィール情報が得られた後に、そのユーザーがこれまでに購入した本のタイトルを取得する場合を考える。
仮にこのユーザーがこれまでに購入した本が5冊だったとすれば、以下のような別のAPIリクエストを叩く必要がある。
https://example.com/api/books/1
https://example.com/api/books/2
https://example.com/api/books/3
https://example.com/api/books/4
https://example.com/api/books/5つまり、特定の人物が購入した本のタイトルを取得したい場合に、
① その人物のプロフィールを取得するためのリクエスト
② それぞれの購入した本の情報を取得するためのリクエスト × 5
と別々のエンドポイントに計6回のリクエストを投げなければならなくなる。
さらにこの本の著者のプロフィールを取得するなどとなれば、さらに多くのリクエストを送信する必要が出てくる。
このように1つのエンドポイントで必要な情報が得られない場合、それを元にして別のエンドポイントにリクエストをかける必要が出てきてしまう。
エンドポイントの膨張
RESTではあるリクエストに対してレスポンスを返す形が決まっているため、クライアント側で変更が加わると、その変更を叶えるために新しいエンドポイントを作成する必要があり、エンドポイントの数が膨れ上がっていってしまう。
リクエスト数を減らすためであれば、/api/people-with-book-titleのようなカスタムエンドポイントを作成することも考えられるが、いずれにせよエンドポイントの数は増えていくし、この次に説明するドキュメント作成の手間が増大してしまう。
APIドキュメントの管理
RESTはリクエストの形とレスポンスの形が決まっているため、何がリクエストに必須で、それぞれのプロパティはどういう型なのかをどこかでドキュメント化するのが良いとされているらしい。
フロントからバックエンドまで一人でやる分には問題ないが、チームとして行う場合は認識のすり合わせが必要になるため。
しかしこういう部分でドキュメントを作成しなければいけなくなると、仕様を変えた時などに更新しなければならなくなりメンテ費用が嵩んでしまう。
GraphQLによる課題の解決
GraphQLを使えば先ほどのような課題は解決できる。
キーとなる特徴は以下の2つだと思っている。
① クライアントからリクエストを行うときに、レスポンスの形を決められる
② スキーマ、フィールドというデータ構造
GraphQLではリクエストを行うときにどういう情報をレスポンスして欲しいかを規定することができる。
以下はIDが1のpersonのname, ageとbooksのtitleだけを取得している例である。
query {
person(personID: 1) {
name
age
books {
title
}
}
}3-7行目がレスポンスの形を規定している部分である。
本来personはgenderやheightなども持っているが、必要ないので取得していない。
このようにしてRESTの時とは違い、過不足なくデータを取得することができる。
また、同一のリクエストでbooksのtitleも取得している。
したがって、複数のリクエストを投げることなく単一のエンドポイントへの1回のリクエストで必要な情報を取ってくることができる。
GraphQLではレスポンスの形をこうしたJSONのようなネスト構造で表すため、とてもわかりやすい。
ここまででRESTの課題①と②は解決できることがわかった。
最後の課題はAPIドキュメントの管理について。
GraphQLでは、リクエストやレスポンスで使用されるデータのプロパティ名や型はスキーマとフィールドというデータ構造で規定する。
スキーマとフィールドは下記のようなものであり、それぞれデータのプロパティ名と型を規定している。
(!がついているものは必須のプロパティ)
type User {
name: String!
age: Int
gender: String
height: Int
...
}
type Book {
title: String!
author: String!
...
}
type Query {
user: User
books: Book
}GraphQLではこのスキーマを使って設計を行うスキーマファーストが重要になり、これによってチームメンバー全員がデータ型について共通の理解をすることができる。
フロントの人が型を定義することもできるようになり、バックエンド任せにすることがなくなる。
ポイントはドキュメントを別で作成しなくてもこのスキーマを見ればどういう型が定義されているのかがわかるようになっていること。
つまり、スキーマそのものがドキュメントの役割をはたすのである。
しかもこれは仕様が変わった際にリアルタイムで変更されるものなので、ドキュメントの更新を忘れたといった事態も防げる。
最初はレスポンスの形をクライアントが自由に決められることがGraphQLのいい点だと思ってたけど、このドキュメントを作成しなくてもいいってのが地味にめちゃくちゃいいのではと最近思うようになった。
というのも、業務をしているとあらゆる場面で認識合わせたり後で確認するためにドキュメントを残すことが必要になることが多い。
必要なのはわかるが、やはりめんどい。書くのもめんどいし、更新しなきゃいけないのもめんどい。
こういうメンテが必要なくなるってのはかなり嬉しいポイントだと個人的には思っている。
ここまでのまとめ
GraphQLを使うことで以下のような嬉しいことがある
GraphQLを使うデメリット
これまでに挙げてきたGraphQLのメリットは素晴らしいものだった。
本とか読んでると、GraphQLは本当に素晴らしいものでメリットがこんなにある!って情報がよく載ってるけど、じゃあデメリットはないのかってのが気になる。
ここでは調べたり社内で議論した結果出てきたGraphQLのデメリットをまとめておく。
キャッシュがしにくい
RESTはそれぞれのAPIリソースに対して固有のURLが与えられるため、そのURLを元にキャッシュキーを生成する事ができる。
GraphQLだと単一のエンドポイントなのでURLベースでのキャッシュが難しい。
この辺もよくわかってないんだけど、ただApollo Clientにはキャッシュの仕組みあるしそんなに問題にならないような気もしているけど詳細は不明。
パフォーマンスの分析が難しい
これもエンドポイントが単一であることが原因。
というのもパフォーマンスの記録や分析というのは通常エンドポイントごとに行うらしい。
ただそれも、Apollo EngineというGraphQLのクエリを分析するミドルウェアが開発されているらしい。
この辺はあまり分からないが、今はもうちょい状況が改善されていたりするのかな?
ヘッダー情報がない
RESTみたいにレスポンスがheaderとbodyみたいに分かれてない。
なのでSet-Cookieしたい場合や、認証情報をヘッダーに含ませてリクエストする場合などに困る?
調べてみるとなんやかんやでできないこともなさそうだけど、処理が煩雑になりそう。
主要なケースは認証情報に関するところだけど、GraphQLでリクエストする前の段階でRESTとかで認証は済ませておくのが無難そうな気がする。
ステータスコードが大体200
GraphQLではエラーが起こっていたとしても大体のステータスコードは200で返ってくる。
その代わり、レスポンスのerrorsキーにエラーの詳細な情報を持たせている。
ステータスコードによる処理の分岐を行いたい場合には困るかも?
ただerrorsキーの内容だったり、Apollo ClientだったらgraphQLエラーで一括でエラーハンドリングできたりするから、ここはあまり困らなさそうな気もする。
N + 1問題
GraphQLではデータ構造がネストになっているため、何もしないとN + 1問題が生じる。
これは遅延読み込みというものを行うことで回避することができるらしく、そのためのdataloaderというライブラリがFacebookから公開されているらしい。
それを使えばN + 1問題は解決されるとのこと。
わりと簡単に実装できるらしい(本当か?)
写真などの重いデータは一気に捌き切れない
詳細は分からないが、シリアライズ方式がJSONでJSONはバイナリのシリアライズが苦手らしい。
うん。。。よく分かんないけどとりあえず重いデータは一気には捌けないらしい。
情報や知見が少ない
これはデメリットではないがやはり使える人がそんなに多くなかったり、情報が出回ってなかったりで苦しそうな印象。
AppSyncのリゾルバーマッピングの書き方が独特で苦しいみたいな話も見聞きする。
結論、いくつかデメリットはあるもののなんやかんやその問題を避ける方法はありそうだし、そのためのツールはこれからどんどん発展していきそうな気がしている。
完全私見だがクリティカルなデメリットはヘッダー情報がないことと、重いデータが一気に捌き切れないくらいだと思っている。
RESTは全てGraphQLに置き換えるべきか?
結論RESTにはRESTの良さがあるし、ケースバイケースだと思っている。
いろんな記事見ててもどうしてもRESTで叩きたくなる時があるって書いてるのを見た。
そしてそういう時は迷わずRESTで叩いたらいいんじゃないかとも。
GraphQLを使うからといってそれだけに固執するのはよくない気がしている。
本にもハイブリッドにして使うのは何も変なことじゃないって書いてた。
個人的な所感としては、GraphQLは設計の段階できちんとスキーマ定義できればかなり有用なツールになり得るんじゃないかと思う。
おわりに
いくつかデメリットもあるものの、個人的にはそれを凌駕するほどのメリットがある気がしている。
自分でAppSync立ててAmplifyと連携させたりして色々触ってみようと思う。
参考


ステータスコードとエラーハンドリング

GraphQLとN + 1問題
