最近Go言語の勉強を始めた。
印象としては簡潔に書けて合理的な言語って感じ。
とにかくシンプルさを追求していてそこがいいところでもありどこか味気なくも感じられる。。笑
Reactを触っていると人によって実装方法が違ったりコーディングの仕方が違ったりするんだけど、その辺かっちり決まってるからコーディング規約とかで宗教戦争みたいなものにならなくて済みそうなので、そこはすごい利点になりそうな気がしている。
誰が書いても同じようなコーディングになるから可読性が上がる代わりに、書いててあまり楽しくないのかなーというトレードオフの関係なのかなと。
前置きはこのくらいにして、今回はGoのポインターについて簡単にまとめてみた。
ポインターって何?
簡単にいうとデータがあるメモリのアドレスのこと
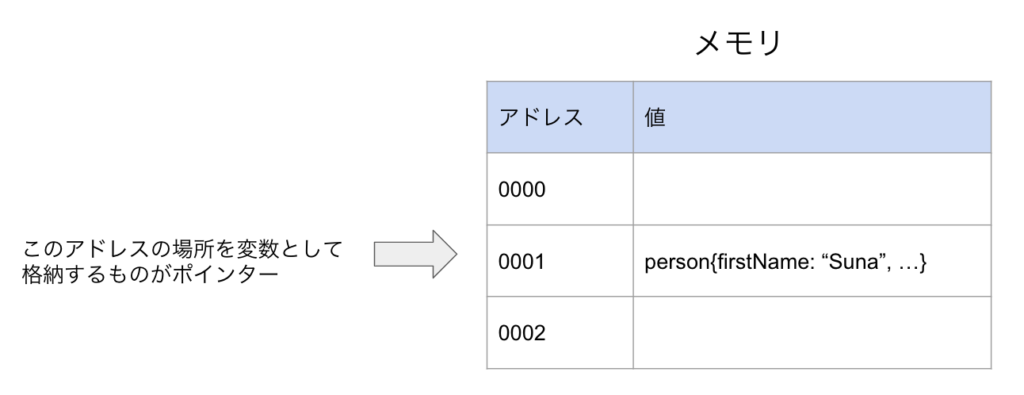
なぜポインターを使う必要があるのか
以下のようなコードを考える。
sunaに対してupdateNameメソッドを使用してfirstNameを”Go”に書き換える。
func main() {
suna := person{
firstName: "Suna",
lastName: "Yu",
}
suna.updateName("Go")
suna.print() // 出力は{firstName:Suna lastName:Yu}
}
func (p person) updateName(newFirstName string) {
p.firstName = newFirstName
}
func (p person) print() {
fmt.Printf("%+v", p)
}しかし、実際に出力されるのは値がupdateされる前の出力である。
なぜこうなるかというと、updateNameに渡されるレシーバーはp person となっており、sunaの値がコピーされて渡されている。
つまり、値渡しになっているので、コピーされたものはupdateされるがオリジナルは変化しないというわけだ。
メモリ上では以下のような感じになっている
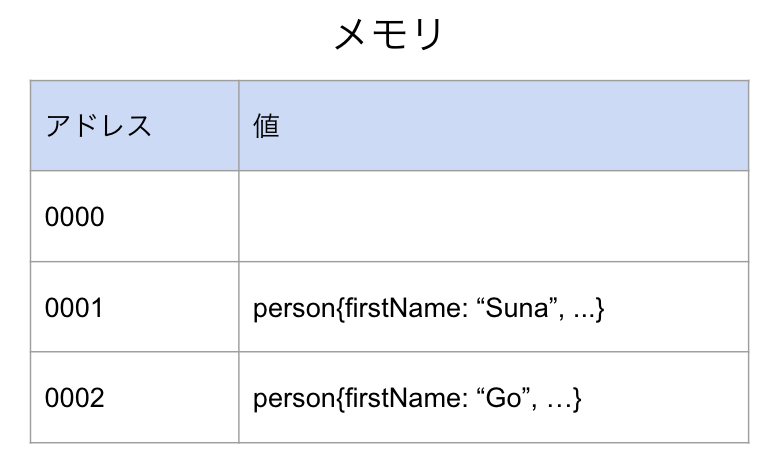
値がコピーされてメモリ上の別の場所で値が更新されてしまっている。
(0002がコピーされたもの)
ではどうすれば元の値を更新することができるのか?
これは関数に情報を渡すときに値を渡すのではなく、値が書かれている場所を渡すことで実現できる。
いわゆる参照渡しというもの。
つまり処理の流れは以下のようになる。
① ポインターによってアドレスを渡す
② アドレスからその値を取得して更新する
この参照渡しをするためにポインターというものが重要になるというわけだ。
ポインターを使った実装
では実際にポインターを使った実装のやり方を見ていく
func main() {
suna := person{
firstName: "Suna",
lastName: "Yu",
}
sunaPointer := &suna //&によってポインターになる(アドレスを指す変数が格納されている)
sunaPointer.updateName("Go")
suna.print() //出力は{firstName:Go lastName:Yu}
}
func (p *person) updateName(newFirstName string) {
(*p).firstName = newFirstName //*をつけることで渡されたアドレスの値を指している。
}
func (p person) print() {
fmt.Printf("%+v", p)
}実装のポイントは以下の通りである。
7行目でポインターを作成してそれを使って関数を呼び出している。
また、12行目で関数のレシーバーが値を受け取る(p person) からポインターを受け取る(p *person) になっている。
13行目で受け取ったポインターから(*p)で値を取り出し更新している。
このようにポインターを使ったやりとりにすることで元の情報にアクセスすることができるようになる。
ちなみに(*p) の部分は単純にp と省略できる。というかこちらの方が一般的。
あと12行目で(p *person) としている場合は、関数に渡すレシーバーの形は値でもポインターでもよくなる。
値を受け取ったときにはGoが勝手にポインターに変換してくれる。
これらを踏まえると最終的にはこう書ける。
func main() {
suna := person{
firstName: "Suna",
lastName: "Yu",
}
suna.updateName("Go")
suna.print() // 出力は{firstName:Go lastName:Yu}
}
func (p *person) updateName(newFirstName string) {
p.firstName = newFirstName
}
func (p person) print() {
fmt.Printf("%+v", p)
}
最初の実装から受け取るレシーバーの形をポインターに変えたのみ。
この辺のどこまでGoが勝手にやってくれるかとかに慣れるのに時間かかりそうな印象。
スライスの参照渡し
これまでで値渡しでは元の情報は書き換えられないということを見てきた。
そこで次のコードを見てみる。
func main() {
mySlice := []string{"A", "B", "C"}
updateSlice(mySlice)
fmt.Println(mySlice)
}
func updateSlice(s []string) {
s[0] = "X"
}これまでの話だとこれは値渡しになるので元の情報は変化しないはずである。
つまり、出力は[A B C]となるはずである。
しかし実際の結果は[X B C]となる。
これはなぜか?
この疑問に答えるために、まずはスライスがどういう構造になっているかを見ていく。
スライスは以下のように実際の値を持っているArray部分と、その配列に対する情報(長さや容量)を持っているSlice部分とに分かれている。
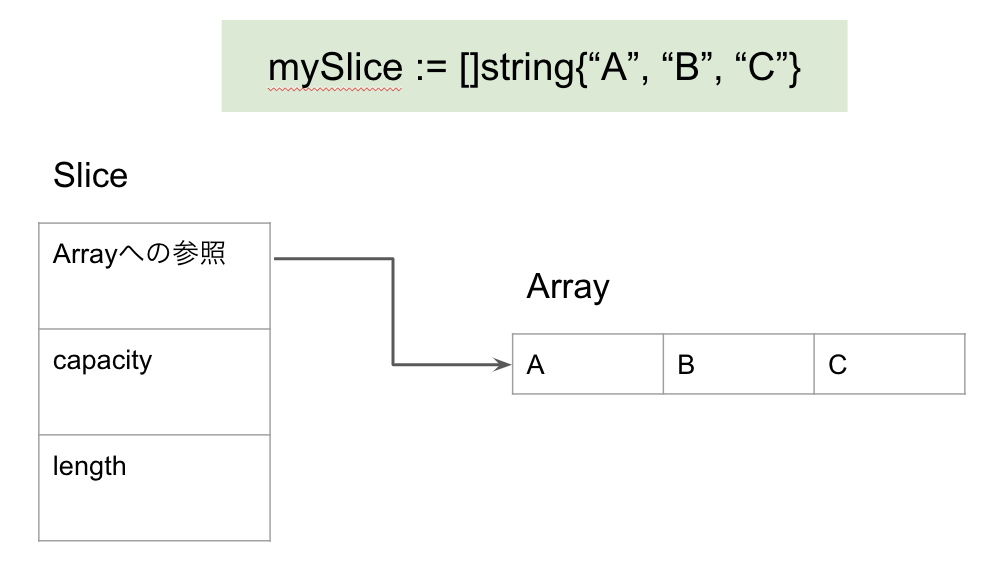
先ほどの例でスライスをそのまま関数に渡したときにメモリ上ではどうなっているのかを示したのが次の図である。
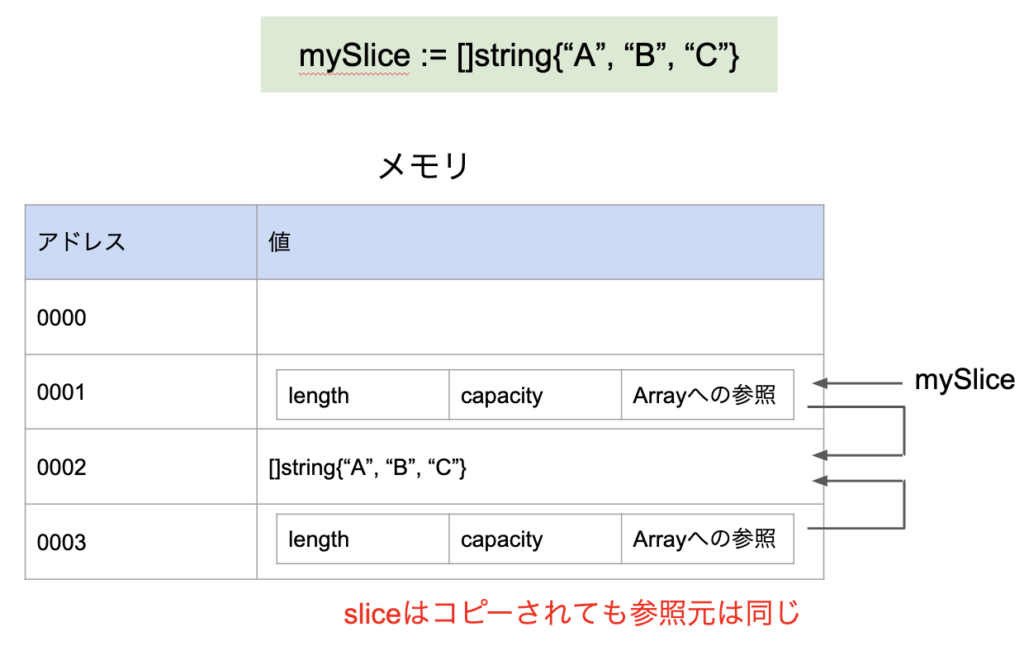
ここに記載した通り、sliceではコピーされた際にArrayに対する情報はメモリの別の場所に確保されるが、そのコピーが指しているArrayは元のArrayと同じものである。
これによってポインターを使わずとも元の情報にアクセスすることができるようになっている。
値型と参照型
slice以外にもこのような挙動を示すものはある。
この違いは変数のタイプに依存しており、具体的には変数が値型であるか参照型であるかによって決まる。
ここまで見てきたような元の情報にアクセスするために、
値型: ポインターを使う必要がある
参照型: ポインターを使う必要がない
値型の変数と参照型の変数(関数)を分類すると以下の通りである。
値型
- int
- float
- string
- bool
- structs
参照型
- slices
- maps
- channels
- pointers
- functions
値型のものはポインターを使う必要がある。
特にstructsは使用頻度も高くポインターを使うことが推奨なので気を付けたい。
おわりに
ポインターの基本的な使い方はだいぶ慣れてきた
sliceでの挙動が意図しなかったものだったが、今回かなり根本的なところから整理できてよかった
インターフェースなどについてもまとめる予定